解决这个问题大概有两种思路:1)尽可能保持住未遮挡区域的响应值,2)把无遮挡区域降低的响应值弥补回来;前者较难,后者则相对容易。一个简单的做法是让检测器学习一个 Spatial-wise Attention,它应在无遮挡区域有更高的响应,然后借助它以某种方式增强原始的特征图。
那么,如何设计这个 Spatial-wise Attention。最简单考虑,它应当是一个 Segmentation Mask 或者 Saliency Map。基于 RetinaNet,FAN 选择增加一个Segmentation 分支,对于学到的 Score Map,做一个 exp 把取值范围从 [0, 1] 放缩到[1, e],然后乘以原有的特征图。为简单起见,Segmentation 分支只是叠加 2 个 Conv3x3,Loss 采用 Sigmoid Cross Entropy。

FAN 的分层 Attention
这里将面对的一个问题是,Segmentation 分支的 groundtruth 是什么,毕竟不存在精细的 Pixel-level 标注。由于人脸图像近似椭圆,一个先验信息是边界框区域内几乎被人脸填满,背景区域很小;常见的遮挡也不会改变「人脸占据边界框绝大部分区域」这一先验。基于这一先验可以直接输出一个以边界框矩形区域为正样本、其余区域为负样本的 Mask,并将其视为一个「有 Noise 的 Segmentation Label」作为实际网络的 groundtruth。我们也尝试根据该矩形截取一个椭圆作为 Mask,但实验结果表明基本没有区别。
这样的 groundtruth 真能达到效果吗?通过可视化已学到的 Attention Map,发现它确实可以规避开部分遮挡区域,比如一个人拿着话筒讲话,Attention Map 会高亮人脸区域,绕开话筒区域。我们相信,如果采用更复杂的手段去清洗 Segmentation Label,实际效果将有更多提高。
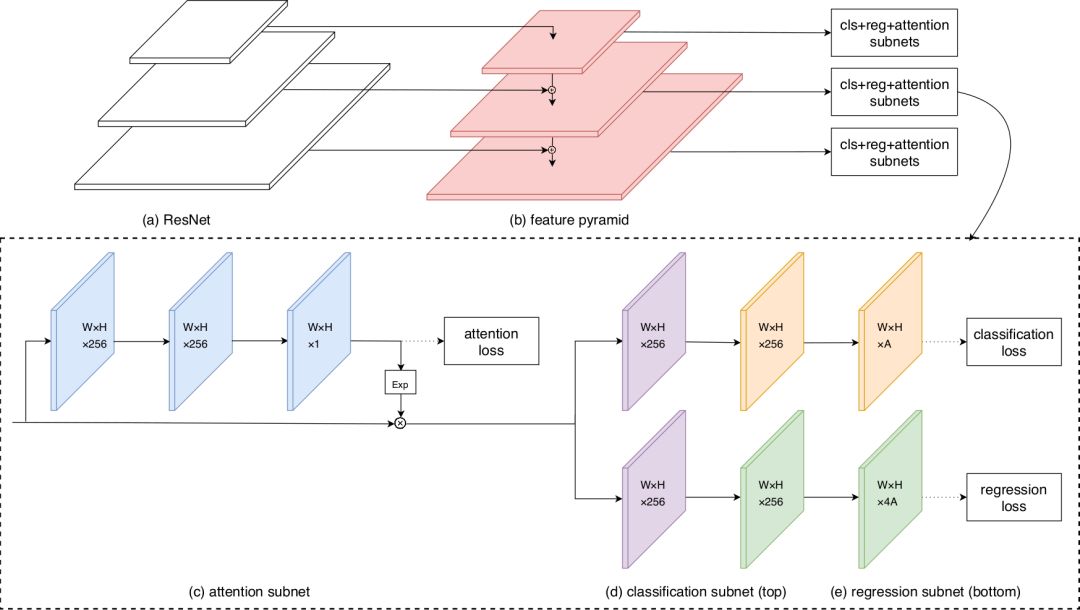
FAN 网络结构
FAN 在 WIDER Face 上曾经保持了半年的 state-of-the-arts。由于仅仅验证方法的可行性,FAN 没有叠加任何 trick,只在原始的 RetinaNet 上调整锚点框,增加我们的 Spatial Attention,因此 FAN 还有很大的上升空间。
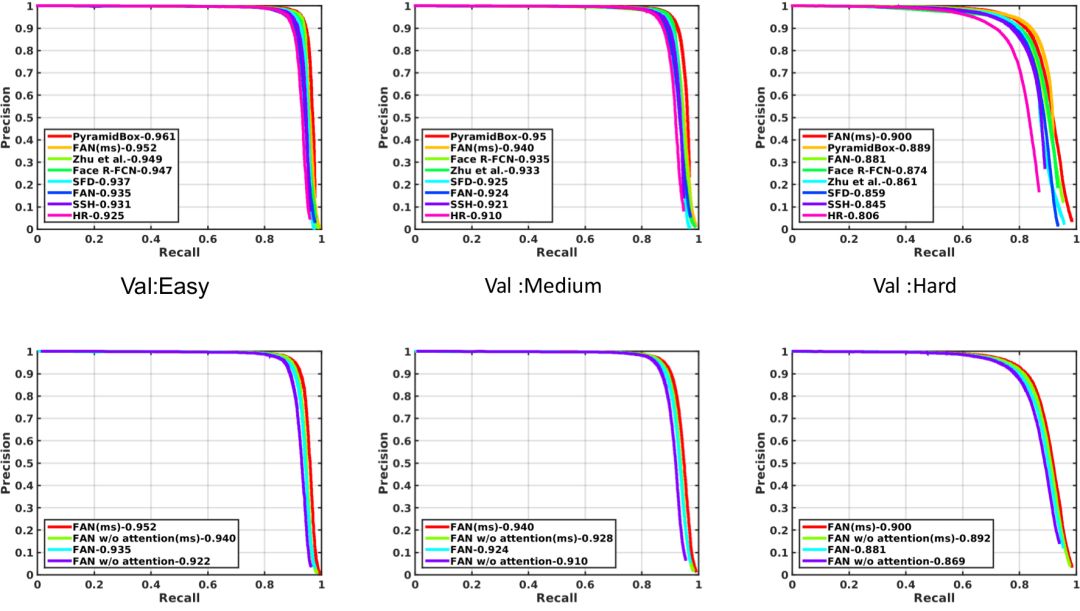
WIDER Face 验证集 的 PR 曲线

FAN 示意图
定位精度:2018 WIDER Challenge Face Detection
第三部分介绍一下旷视科技夺魁 2018 WIDER Face and Pedestrian Challenge 的解决方案。2018 WIDER Challenge 有 3 个 track,旷视参战了其中的 Face Detection。更多信息请参见:ECCV 2018 | 旷视科技夺获人工智能顶赛Wider Challenge人脸检测冠军。

2018 WIDER Challenge Face Detection 排名
Face Detection 使用 WIDER Face 数据集原始图像,但是 Label 做了一定 Refine。据我们统计,Label 数量稍多于原数据集,导致在不对模型做任何更改的情况下,使用新Label 也会比原 Label 涨点(因此笔者建议为公平对比,今后引用 WIDER Face 的论文最好注明是使用了 WIDER Face Label 还是WIDER Challenge Label)。此外,WIDER Challenge 数据集不同于 WIDER Face 数据集的是,使用了相同于 MS COCO 的Metrics,这意味着对模型的回归能力提出了更高的要求。
旷视夺冠的方法仍然基于 RetinaNet。通过对比常见 Backbone,我们给出了以下表格的结果。可以发现,更强的 Backbone 并不意味着更好的 Detection能力。一些 Backbone 分类能力更强,但是提供的 Feature 或者分层 Feature并不够好;感受野等对 Detection 至关重要的因素也不合适;对于二分类问题而言也存在过拟合现象。由于实验周期等原因,我们最后简单选择了 ResNet 50 和 DenseNet 121 继续后面的实验。需要声明的是,它们在很多情况下都不是最优 Backbone,我们有必要思考何种Backbone 提取的特征最适合做检测。
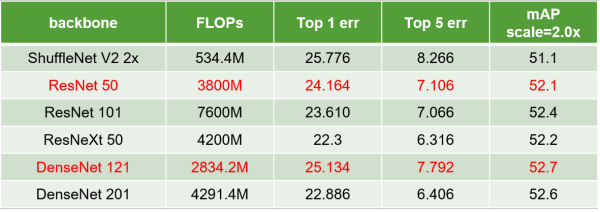
不同 Backbone 的比较
我们在 Backbone 上应用了 GAP trick,这在上篇知乎专栏(ycszen:语义分割江湖的那些事儿——从旷视说起)有所介绍。该 trick 同样适用于 Detection。我们还使用了Deformable Conv,但其贡献主要是扩大 ResNet 原本不高的感受野。
对于 Head 部分,我们首先将 Smooth L1 Loss 换成 IoU Loss,这是为照顾数据中占比较多的小脸,但实际分析一下可以发现,在锚点框合适的情况下,IoU Loss 的提升会很微小。我们对 Head 的主要改动是做一个简单的 Cascade。Cascade R-CNN[12] 是最早通过做 Cascade 提升模型 Regression能力的方法,我们希望将其移植到单步检测器上。

Cascade R-CNN
可以发现,具体做法部分借鉴了 SFace,即把前一个 Stage 的预训练边界框与 groundtruth 边界框之间的 IoU 作为下一个 Stage 的 Classification Label;随着 IoU 逐渐提升,每个 Stage 的 IoU threshold 也逐渐增大,这与 Cascade R-CNN 很类似。
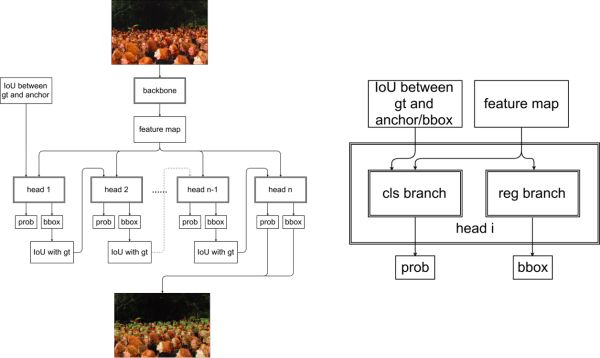
旷视使用的 Single-Stage Cascade 方案
这个 Cascade 方案不难想到,也简单易行,但是的确涨点,Inference 时也只需保留最后一个 Stage,不会增加 Inference 成本;这个方案也有自己的问题,最大的是每个Stage 在共用同一个 Feature Map,对此已有相关论文提出改进。
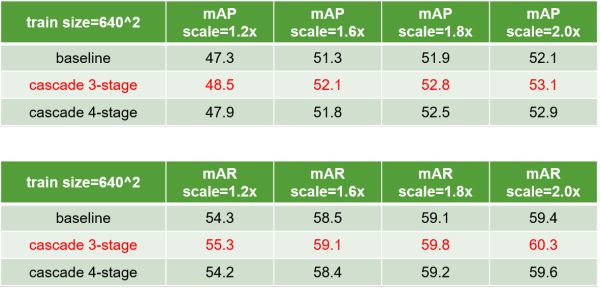
Single-Stage Cascade 的 Ablation Study
此外,我们还在 Data Augmentation、Ensemble 等方面做了改进,由于比较 Trivial,这里不再赘述。我们曾在 ECCV 2018 Workshop 展示过该方案,更多内容请查阅 slides:
WIDER Face Challenge workshop.pptx
作者简介
王剑锋,北京航空航天大学软件学院硕士,旷视科技研究院算法研究员,研究方向人脸检测、通用物体检测等;人脸检测算法 SFace 和 FAN 一作;2018 年参加计算机视觉顶会 ECCV 挑战赛 WIDER Challenge 获得人脸检测(Face Detection)冠军。












 粤公网安备 44010602004352号
粤公网安备 44010602004352号