什么是其他类型的人工智能?
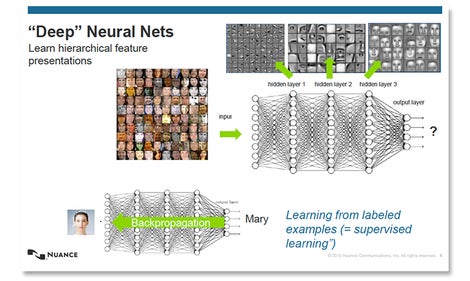
深度神经网络的结构和训练
人工智能研究的另一个领域是进化计算。
它借用了达尔文的自然选择理论。它看到遗传算法在几代人之间进行随机变异和组合,试图进化出一个给定问题的最佳解决方案。
这种方法甚至被用来帮助设计人工智能模型,有效地利用人工智能来帮助建立人工智能。这种使用进化算法来优化神经网络的方法被称为神经进化。随着智能系统的使用越来越普遍,特别是在对数据科学家的需求经常超过供应的情况下,它可以在帮助设计高效的人工智能方面发挥重要作用。Uber人工智能实验室展示了这种技术,它发布了关于使用遗传算法训练深度神经网络以解决强化学习问题的论文。
最后,还有专家系统,即用规则对计算机进行编程,使其能够根据大量的输入做出一系列决定,使机器能够模仿人类专家在特定领域的行为。这些基于知识的系统的一个例子可能是,例如,驾驶飞机的自动驾驶系统。
是什么推动了人工智能的复苏?
如上所述,近年来人工智能研究的最大突破是在机器学习领域,特别是在深度学习领域。
这在一定程度上是由数据的容易获得所推动的,但更多的是由并行计算能力的爆炸性增长所推动的,在此期间,使用图形处理单元(GPU)的集群来训练机器学习系统变得更加普遍。
这些集群不仅为训练机器学习模型提供了更强大的系统,而且它们现在作为云服务在互联网上广泛提供。随着时间的推移,主要的科技公司,如谷歌、微软和特斯拉,已经转向使用专门的芯片,为运行和最近训练机器学习模型而定制。
这些定制芯片的一个例子是谷歌的张量处理单元(TPU),其最新版本加速了使用谷歌TensorFlow软件库建立的有用的机器学习模型从数据中推断信息的速度,以及它们的训练速度。
这些芯片被用来训练DeepMind和谷歌大脑的模型,以及支撑谷歌翻译和谷歌照片中的图像识别的模型,以及允许公众使用谷歌的TensorFlow研究云建立机器学习模型的服务。这些芯片的第三代在2018年5月的谷歌I/O大会上亮相,此后被打包成机器学习的强者,称为pods,每秒可以进行超过十万亿次浮点运算(100 petaflops)。这些正在进行的TPU升级使谷歌能够改善其建立在机器学习模型之上的服务,例如,将谷歌翻译中使用的模型训练时间减少一半。
机器学习的要素是什么?
如前所述,机器学习是人工智能的一个子集,一般分为两大类:有监督的学习和无监督的学习。
监督下的学习
教导人工智能系统的一个常见技术是通过使用许多标记的例子来训练它们。这些机器学习系统被灌输了大量的数据,这些数据已经被注释过,以突出感兴趣的特征。这些数据可能是标明是否包含一只狗的照片,或者是带有脚注的书面句子,以表明"低音"一词是与音乐还是与鱼有关。一旦经过训练,系统就可以将这些标签应用于新的数据,例如,应用于刚刚上传的照片中的一条狗。
这种通过实例教导机器的过程被称为监督学习。给这些例子贴标签通常是由通过亚马逊Mechanical Turk等平台雇用的在线工人进行的。
训练这些系统通常需要大量的数据,一些系统需要搜索数百万个例子来学习如何有效地执行一项任务--尽管在大数据和广泛的数据挖掘时代,这越来越有可能。训练数据集是巨大的,而且规模越来越大--谷歌的开放图像数据集有大约900万张图像,而其标记的视频库YouTube-8M链接到700万个标记的视频。ImageNet是早期的此类数据库之一,拥有超过1400万张分类图像。它是由近5万人(其中大部分人是通过亚马逊Mechanical Turk招募的)在两年内汇编而成的,他们对近10亿张候选图片进行了检查、分类和标注。
从长远来看,获得巨大的标签数据集也可能证明不如获得大量的计算能力重要。近年来,生成对抗网络(GANs)已被用于机器学习系统,它只需要少量的标记数据和大量的无标记数据,顾名思义,这些数据需要较少的人工准备。这种方法可以让人们更多地使用半监督学习,在这种情况下,系统可以学习如何使用比现在使用监督学习训练系统所需的更少的标记数据来执行任务。
无监督学习
相比之下,无监督学习使用了一种不同的方法,算法试图识别数据中的模式,寻找可以用来对数据进行分类的相似性。一个例子可能是将重量相似的水果或发动机尺寸相似的汽车聚在一起。该算法并不是事先设置好的,以挑选出特定类型的数据;它只是寻找其相似性可以分组的数据,例如,谷歌新闻将每天类似主题的故事分组。
强化学习
强化学习的一个粗略的比喻是,当一只宠物玩了一个小把戏时,它就会获得奖励。在强化学习中,系统试图根据其输入数据最大化奖励,基本上经历了一个试错的过程,直到达到最佳结果。
强化学习的一个例子是谷歌DeepMind的深度Q网络,它被用来在各种经典视频游戏中获得最佳人类表现。该系统从每个游戏中获取像素,并确定各种信息,如屏幕上物体之间的距离。
通过查看每场游戏中取得的分数,该系统建立了一个模型,即在不同情况下哪个动作会使分数最大化,例如,在视频游戏《突围》中,为了拦截球,球拍应该移到哪里。这种方法也被用于机器人研究中,强化学习可以帮助教导自主机器人在真实世界环境中的最佳行为方式。
哪些是人工智能领域的领先公司?
随着人工智能在现代软件和服务中发挥着越来越重要的作用,每个主要的科技公司都在努力开发强大的机器学习技术,供内部使用并通过云服务向公众出售。
每家公司都经常因在人工智能研究方面取得新突破而成为头条新闻,尽管可能是谷歌及其DeepMind人工智能AlphaFold和AlphaGo系统对公众对人工智能的认识产生了最大的影响。
哪些人工智能服务是可用的?
所有主要的云平台--亚马逊网络服务、微软Azure和谷歌云平台--都为训练和运行机器学习模型提供了GPU阵列,谷歌也正在准备让用户使用其张量处理单元--其设计为训练和运行机器学习模型而优化的定制芯片。
所有必要的相关基础设施和服务都可以从三巨头那里获得,基于云的数据存储,能够容纳训练机器学习模型所需的大量数据,转换数据以准备分析的服务,清晰显示结果的可视化工具,以及简化模型构建的软件。
这些云平台甚至简化了自定义机器学习模型的创建,谷歌提供了一项自动创建人工智能模型的服务,称为Cloud AutoML。这种拖放式服务可以建立自定义的图像识别模型,并要求用户没有机器学习的专业知识。
基于云的机器学习服务正在不断发展。亚马逊现在提供了大量的AWS产品,旨在简化机器学习模型的训练过程,最近还推出了Amazon SageMaker Clarify,这个工具可以帮助企业消除训练数据中可能导致训练模型预测偏差的偏见和不平衡现象。
对于那些不想建立自己的机器学习模型,而是想消费人工智能驱动的按需服务,如语音、视觉和语言识别的公司来说,微软Azure因其提供的服务广度而脱颖而出,紧随其后的是谷歌云平台和AWS。同时,IB+M除了提供更普遍的按需服务外,还试图销售针对特定行业的人工智能服务,从医疗保健到零售,将这些服务集中在IBM Watson旗下,并投资20亿美元收购了气象频道,以释放数据宝库,增强其人工智能服务。
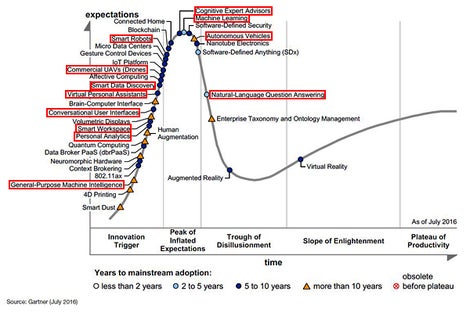
许多与AI 相关的技术正在接近或已经达到Gartner 炒作周期中的“期望过高的峰值”,而由强烈反对驱动的“幻灭低谷”正在等待中。












 粤公网安备 44010602004352号
粤公网安备 44010602004352号