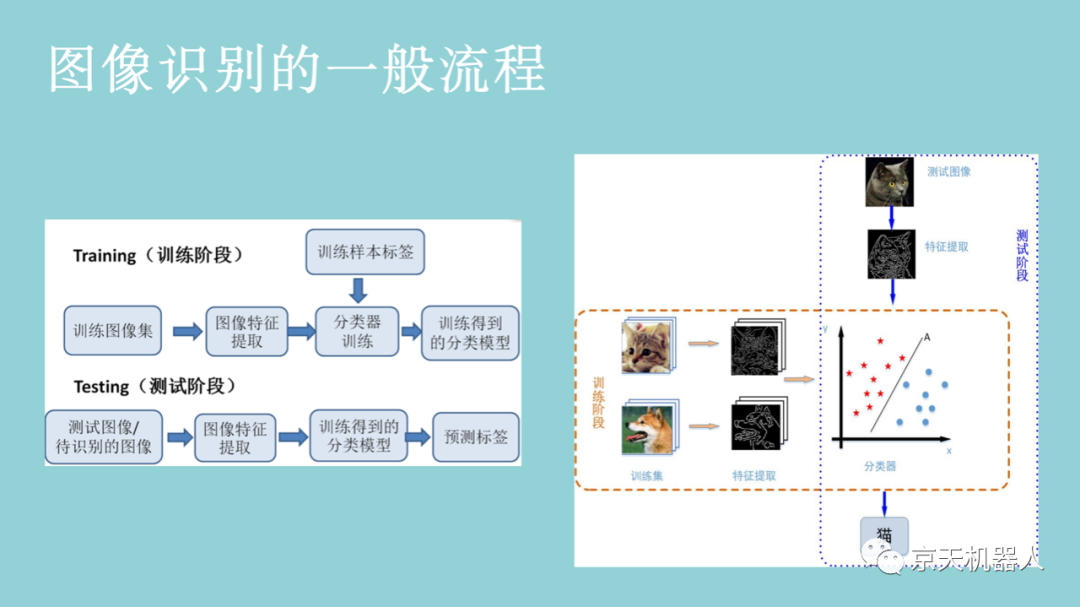
图4-5则是以猫和狗为识别目标的一个图像识别系统。系统需要一些猫和狗的图像,通过这些图像学习出猫和狗各自的特征(例如猫和狗的轮廓不一样),再通过对猫狗特征的学习获得能够分辨猫狗的分类器。在训练好猫狗分类器以后,当有新的猫或者狗的图像输入到系统时,系统首先将图像转换成特征,然后使用已经学习好的猫狗分类器就能自动识别出是猫还是狗。需要注意的是,系统只能对已经学习过的类别进行识别。例如,识别系统只训练学习了狗和猫的图像,那么该系统只能识别狗和猫的图像。如果你给这个系统一只狐狸的图像,该系统则无法识别。
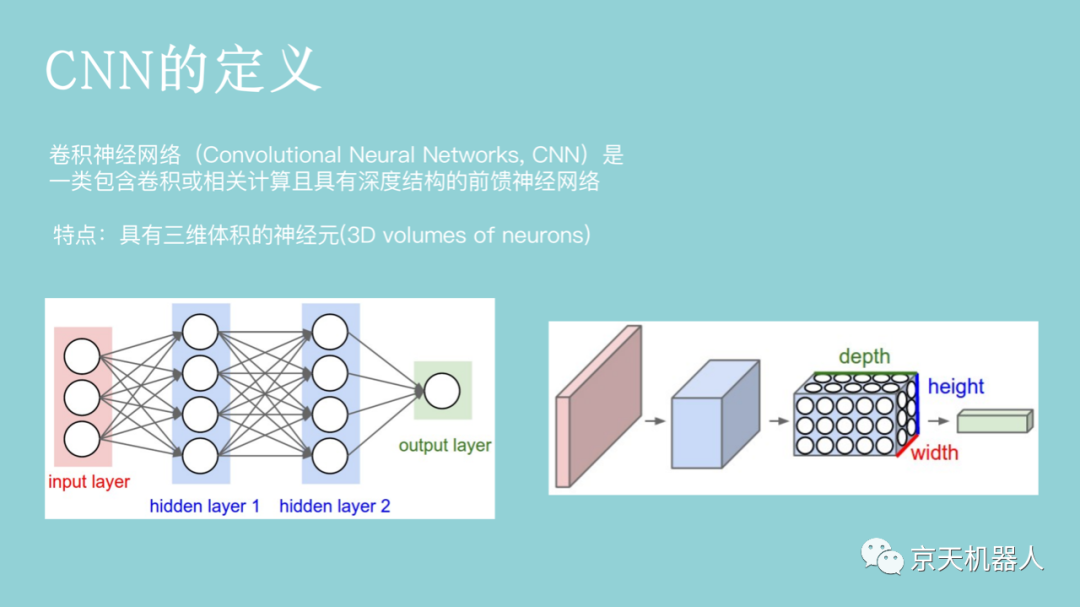
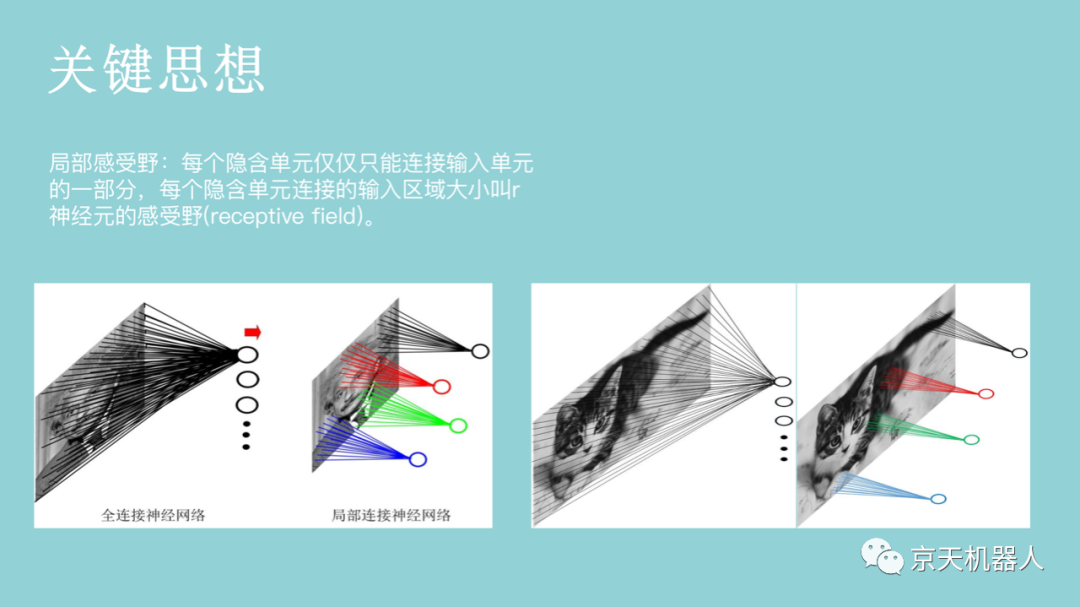
通常,输入的原始图像有太多冗余的信息,而这些信息不是分类所必需的。因此,图像分类的第一步是通过提取包含在图像中的重要信息并舍弃其余部分来简化图像。例如,我们可以通过使用边缘检测器,将图像中物体的边缘信息提取出来。该步骤称为特征提取。在传统的计算机视觉方法中,设计这些特征对算法的性能是至关重要的。除了简单的边缘特征以外,我们可以进一步提取其它更有用的特征。常用的图像特征包括Haar特征、HOG(Histogram of Oriented Gradients)特征、SIFT(Scale-Invariant Feature Transform)特征、SURF特征(Speeded Up Robust Feature)等。一旦获取了图像特征,我们就可以通过前面章节所学的分类学习方法对图像进行分类。图像识别常用的分类学习方法主要包括支持向量机、最近邻分类器、人工神经网络、深度学习等。














 粤公网安备 44010602004352号
粤公网安备 44010602004352号